Question
Web Crawler
Step 1 - Understand the problem and establish design scope
Questions to ask
- What is the purpose of the crawler? Indexing, data mining...
- How many web pages does the web crawler collect per month?
- What types are included?
- Only HTML or other types as well
- Shall we consider the newly added or edited pages?
- Do we need to store HTML pages crawled from the web?
- How do we handle web pages with duplicated content?
Functional requirements
- Search engine indexing
- 1 billion page per month
- HTML only
- Store content up to 5 years
- Ignore pages with duplicate contents
Non-functional requirements
- scalability - there are billions of web pages out there
- Web crawling should be extremely efficient using parallelisation
- robustness - Bad HTMLs, malicious links...
- politeness - not make too many requests to a website within a short time interval
- extensibility - System is flexible so that minimal changes are needed to support new content types
Back of the envelop estimation
- 1 billion web pages downloaded every month
- around 400 pages per second
- assume the peak QPS to be 800
- Assume average web page size is 500 KB
- 1 billion * 500k is around 500TB per month
- Assume data are stored for 5 years
Step 2 - Propose high-level design and get buy-in
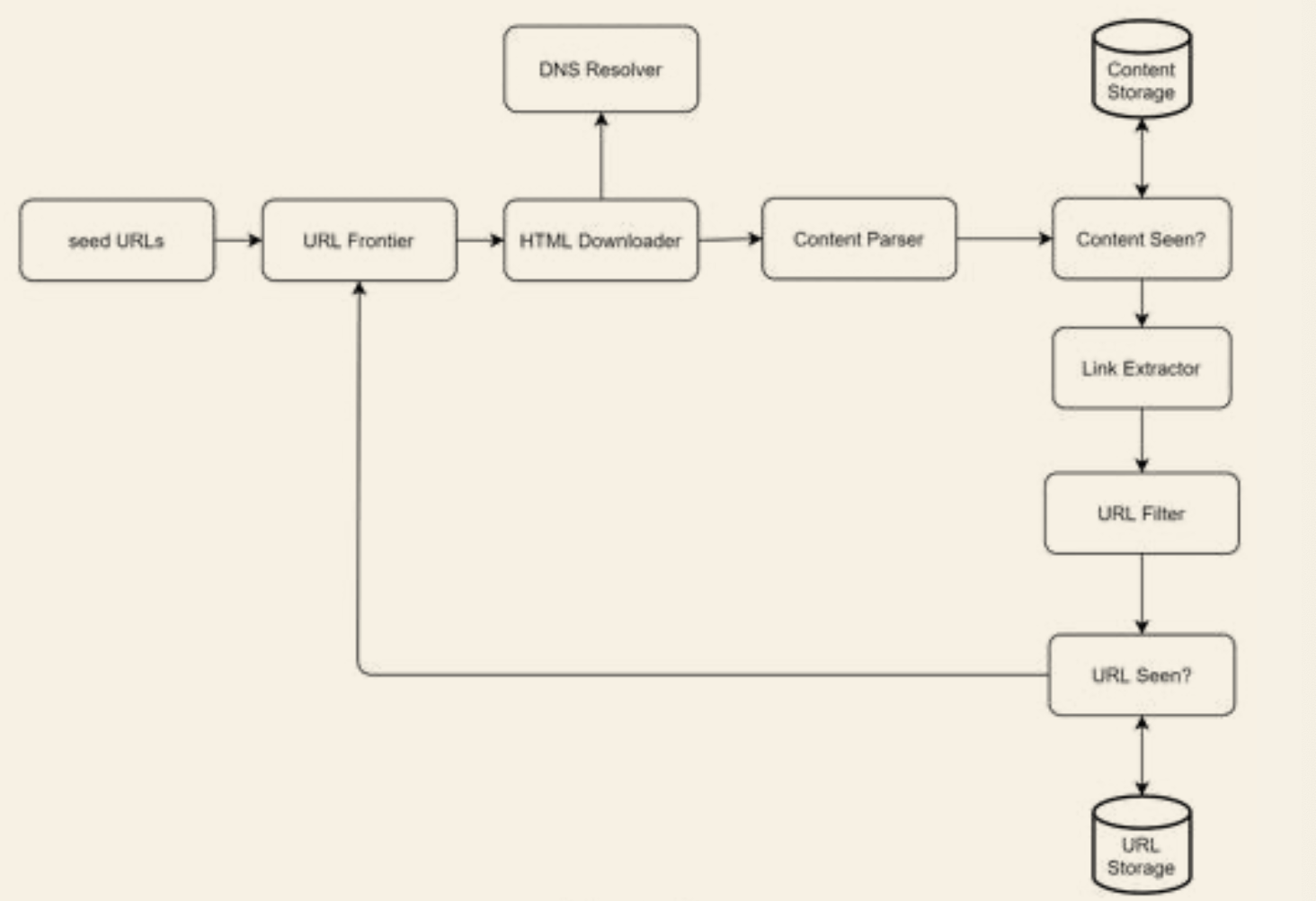
Seed URLs
- Starting point of the crawl process
- Try to divide the large URL space into smaller ones
- Base on location, types of the website and such
URL Frontier
- To store URL to be downloaded
- Usually in FIFO queue
HTML Downloader
- From the internet, where URL is provided by the Frontier
DNS resolver
- Convert the URL into IP address
Content parser
- Should be parsed and validated
- Remove malformed page to save up storage
- Move into a seperate component to prevent slowing down the crawling process
Content Seen
- Remove duplicates
- Compare the hash values of two web pages to improve efficiency
Content storage
- Popular content is kept in memory
- Most other content is stored on disk
- Parse and extract links from HTML pages
URL Filter
- Excludes certain content types, file extensions, error links and URL in "blacklisted" sites
URL Seen
- Remove seen and URL on Frontier
- Avoid infinite loop
- Can implement using bloom filter
URL Storage
Step 3 - Design deep dive
DFS vs BFS
- DFS is not ideal since it may recurse to a really deep level
- The BFS approach is also problematic in two ways:
- Most links from the same page are linked to the same host (such as wikipedia). Which may result too many request sent to the server, which is "impolite"
- Standard BFS does not take the priority of URL into consideration
- Hence need to modify to prioritise URLs according to their page rank, web traffic, update frequency...
URL frontier
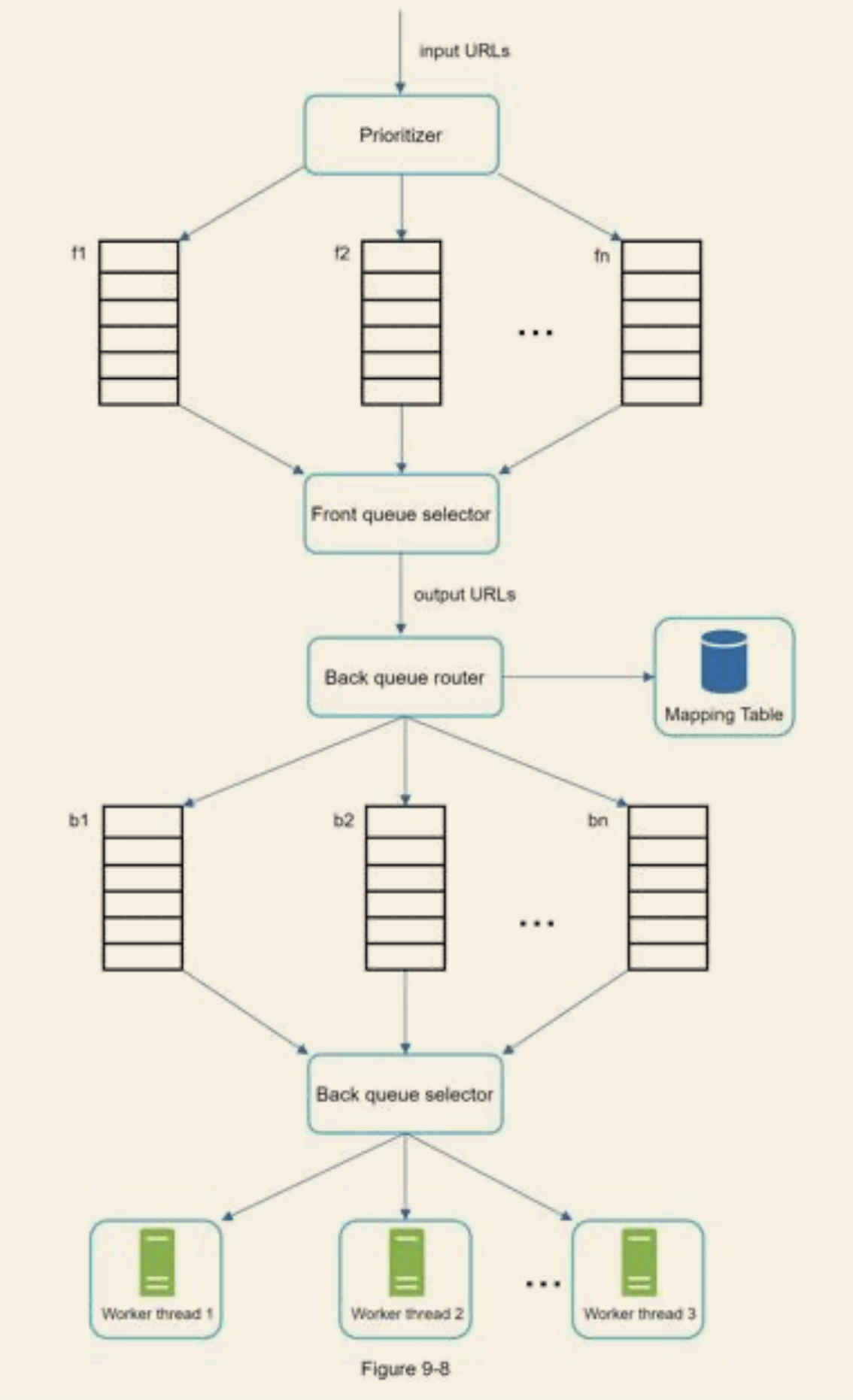
Politeness
- Reduce request sent to the same server to avoid been treated as DOS attack
- Enforcing download one page at a time from the same host
Priority
- can be measured by page rank, web traffic, update frequency...
- Instead of seperate URL into queues by their domain, can seperate by the importance of the URL
Freshness
- Recrawl based on web pages's update history
- Prioritise URLs and recrawl important pages first and more frequently
Storage for URL Frontier
- Majority of URLs are stored on disk, so that the storage is not an issues
- Maintain buffers in memory for enqueue/dequeue operation
- Data in buffer is periodically written to the disk
HTML Downloader
Robots.txt
- Standard used by websites to communicate with crawlers
- Indicates which pages are allowed to download
- Distributed crawl
- Multiple servers and threads
- Cache DNS resolver
- When one thread is making request to DNS server, other threads are block temporarily from 10ms to 200ms
- We can maintain our own DNS mapping from URL to IP address
- Updated periodically by cron jobs
- Locality
- When crawler is closer to the server host, the download time is faster
- Short timeout
- Some web server responds slowly
- Hence need to set a timeline, and terminate the request if non-responsive
Robustness
- Consistent hashing
- Distribute loads among downloaders
- Save crawl states and data
- Disrupted crawl can be restarted easily by loading saved states and data
- Handel exception gracefully
- Data validation
Extensibility
- Can easily plugin modules such as PNG downloader, web monitor modules...
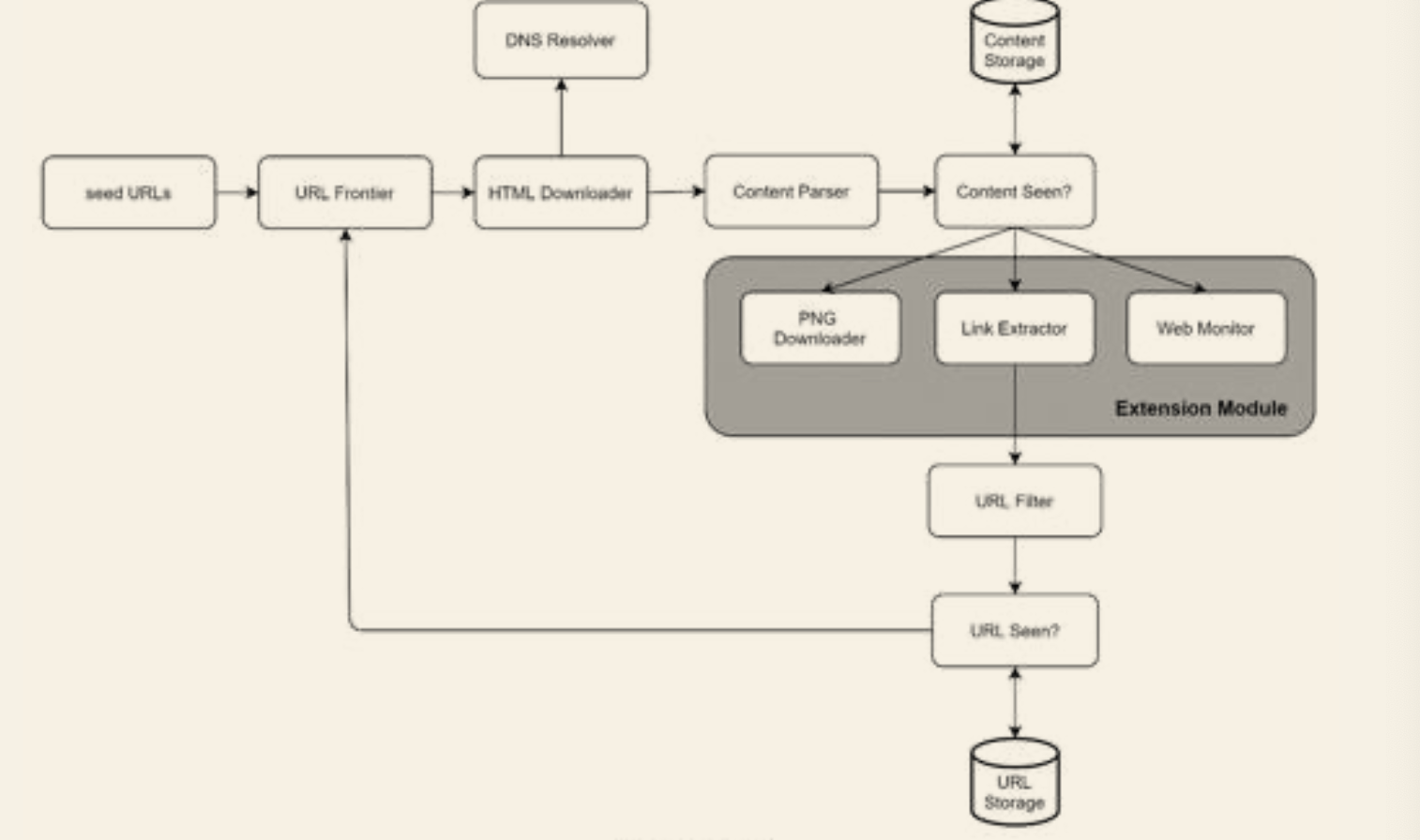
Detect and avoid problematic content
- Redundant content
- Spider traps - a infinite deep directory structure
- Data noises - data with no value such as advertisements
Step 4 - Wrap up
- Server-side rendering
- To address to dynamically generated links, perform server-side rendering first before parsing
- Filter unwanted pages
- Database replication and sharding
- Availability, consistency and reliability
- Analytics