If the size of the data is relatively small and can fit on a node)
ACID
Atomicity
each transaction is all or nothing
transaction fail if it did not complete
Consistency
Any transaction will bring the database from one valid state to another
constraints set by the database, such as foreign key constraints
Isolation
Executing transactions concurrently has the same results as if the transactions were executed serially
Durability
Once a transaction has been committed, it will remain so
Methods of scale
Replication
Potential loss of data if the master fail before replication
If write is frequent, the read replicas can get bogged down by replaying writes, and can't do much of reads
Increased slaves/nodes -> more replications -> increased latency
Hardware cost and complexity
Master-slave replication
The master serves read and write
If master goes offline, the system will become read-only mode util a slaved is promoted to a new master
Slaves only serves read
Slaves and replicate to additional slave in tree-like fashion
Disadvantages
Additional logic required to promote slave to master
Higher stale data, mainly used if user are from vastly different geo locations
Master-master replication
All masters servers both read and writes
If either goes done, system remains to operate
Disadvantages
Need load balance or change on application logics to know where to write
Most master-master systems are either violate ACID or increased write latency due to synchronisation
Need to resolve conflict when writing on multiple nodes
Federation
Or know as functional partitioning, splits the database by functions
Rather a monolithic database, you could have three: forums, users, and products
Advantages
Less read and write request to each -> less replication lag
Improve cache hit, since larger proportion of data can be stored in memory
Can write in parallel to further efficiency
Disadvantages
Not efficient if schema requires huge functions or tables
Update logic to know where to read and write
Joining from two databases is more complex
Hardware complexity
Sharding
Distribute data across difference databases such that each database can only manage a subset of the data
Usually use user's last name or geographic locations
MySQL and Postgres do no support sharding natively
Advantages
Less read and write request to each -> less replication lag
Improve cache hit, since larger proportion of data can be stored in memory
Can write in parallel to further efficiency
Disadvantages
Update logic to know where to read and write, result in complex SQL queries
Joining from multiple shards is more complex
Data distribution can become lopsided in a shard. For example, a set of power users on a shard could result in increased load to that shard compared to others.
Rebalancing adds additional complexity, can use consistent hashing to reduce the complexity
Hardware complexity
Denormalisation
Redundant copies of the data are written in multiple tables to avoid expensive joins.
Disadvantage(s):
Data is duplicated.
Constraints can help redundant copies of information stay in sync, which increases complexity of the database design.
A denormalised database under heavy write load might perform worse than its normalised counterpart.
SQL tuning
Important to benchmark and profile to simulate and uncover bottlenecks
Benchmark - Simulate high-load situations
Profile - tracking performance issues
Optimisations
Tighten up the schema
Avoid BLOB storage
Use CHAR instead of VARCHAR for fixed length strings
Use good indices
Columns that you are querying (SELECT, GROUP BY, ORDER BY, JOIN) could be faster with indices.
Indices are usually represented as self-balancing B-tree that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time.
Avoid expensive joins
Tune the query cache
NoSQL
Why NoSQL
If the data to be stored is unstructured
If there's a need to serialise and deserialise data
If the size of the data to be stored is large
Favour eventual consistency
limited by the scale
BASE
Basically available - the system guarantees availability.
Soft state - the state of the system may change over time, even without input.
Eventual consistency - the system will become consistent over a period of time, given that the system doesn't receive input during that period.
Key-Value store
Redis, DynamoDB
For rapidly changing data
Just like an hash-map
flat in nature
used for session oriented applications
Maintain keys in lexicographic order, allowing efficient retrieval of key ranges.
Document Store
MongoDB
For high flexibility, and occasionally changing data
such in JSON, XML, binary formate
key points to a hierarchical structure
unstructured catalog data
Provides APIs or a query language to query based on internal structure of the document itself
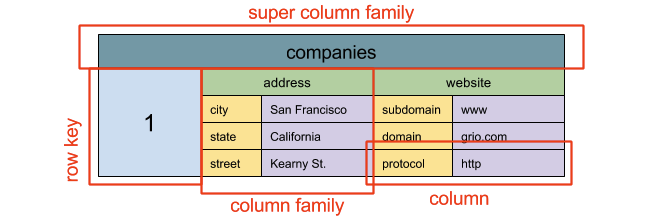
Wide Column Store
- Cassandra, Bigtable
- high availability and high scalability
for large volume of write
don't need to update and read a lot
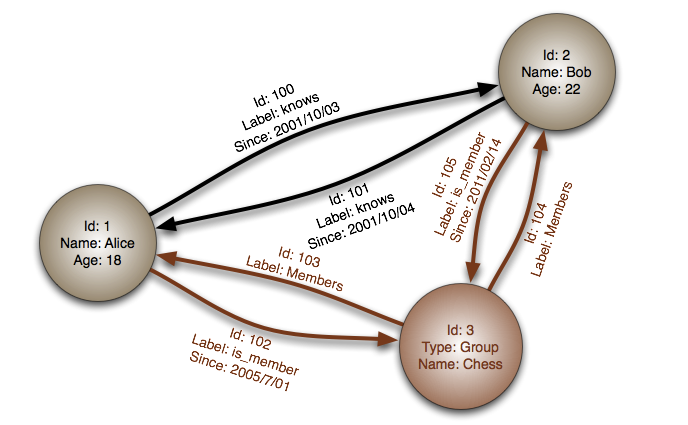
Graph database
network structure such as social media networks
social applications
Most can only access with REST APIs
SQL or NoSQL
Reasons for SQL:
Structured data
Strict schema
Relational data
Need for complex joins
Transactions
Clear patterns for scaling
More established: developers, community, code, tools, etc