Why hashing
- Easy to scale horizontally since data are more evenly distributed
Question
Standard hashing
- The hashing id of each server might change when server been added or remove, causing almost all keys to be remapped
- Increase cache miss hence inefficiency
Consistent hashing
- Assume we use SHA-1 as hash function, the output range is from x0 to x_n.
- SHA-1's hash space goes from 0 to 2^160 - 1
- Map servers and keys on the ring using a uniformly distributed hash function
- To find the server, go clockwise until the server is located
- Add a new or remove server requires redistribution of a fraction of keys
Two issues of basic approach
- Impossible to keep the same size partition on the ring across all servers
- It is possible to have a non-uniform key distribution on the ring
Virtue nodes
- Increased space complexity to reduct imbalance
- The SD is between 5% (200 virtual nodes) and 10% (100 virtual nodes) of the mean
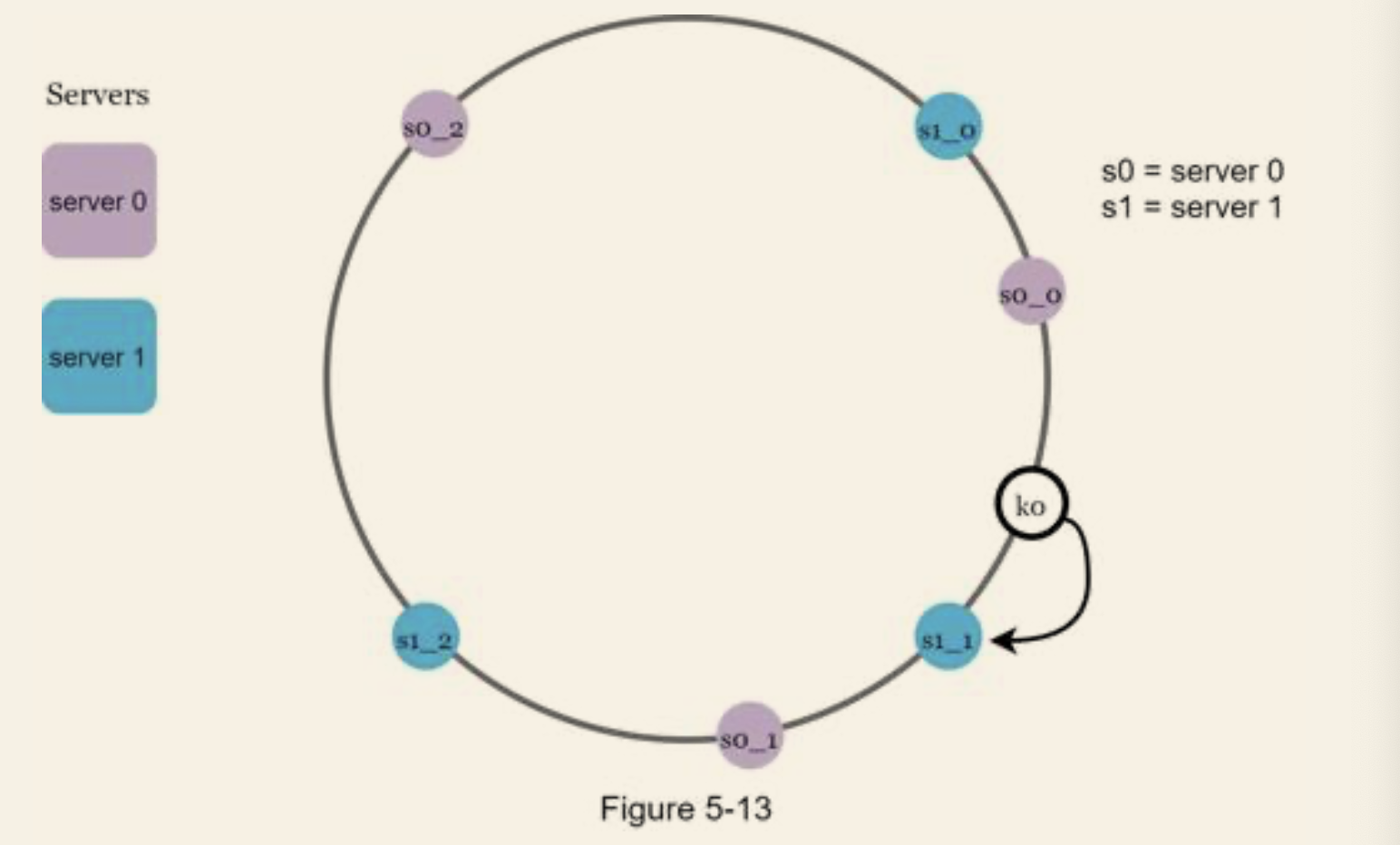
Find affected keys
- Move anti-clockwise, then redistribute all keys located between the server to the newly allocated server